Part 1 - Orwellian AI
This is mostly a story of how I didn’t think through the implications of the software I was building.
The Challenge
My brother is a bootstrapped founder for a small, mildly successful startup. One day he starts a conversation that goes something like:
> Oh man, I’m juggling so much at work.
> I can’t look away from Marketing, Sales, Engineering, or Product.
> When I’m leading sales, I spend time away from Product, and they start working on the wrong things.
> Everyone works hard, but it’s me. I don’t scale.
> Is that something LLMs can help with? We have so much unstructured data laying around.
Oooo, a direct challenge.
I put my PM hat on - here are the use-cases:
- “Hey, what’s the engineering team working on?”
- “What’s the last thing anyone did on Project Z”
- “Which projects have been moving slowly”
- “What are our longest-running initiatives”
- “what projects are blocked”
- “who looks like they need help”
- “Who are the main drivers of Project Y”
I talked to the engineers and, to my surprise, they also wanted this. In a fast moving startup, they too have to juggle multiple tasks. If there was a tool that had a high-level overview of what others were working on then they could be in less meetings. We were all a little skeptical though.
> “The standup is just status theater,” one remarked.
> “Yeah! Those EMs keep talking about replacing engineering jobs. Let’s see how the shoe fits!” a junior engineer said in jest.
This is the type of low-risk side-project that I like to do for my brother’s startup. The expectations from everyone that I’d deliver anything was super-low (including myself). I timeboxed it into a week.
I asked around for the major sources of information only to find that there were many places where work happened. The plan was simple - build a daily batch pipeline that indexed a giant DB (RAG) of these “work-artifacts”, and hand it over to an LLM who can query it agenticly.
The architecture
Key Term - An “artifact” is any facet of work: Jira, Docs, Doc-comments, Slack, Calendar, PRs, PR-review-comments, transcribed meeting notes, etc.
One day I’ll do a full technical writeup. After many trials and failures I settled on an Agentic RAPTOR RAG. This produces a tree, where the leaf nodes are work-artifacts, and the higher up nodes are summaries. I like architectures that resembles the real world, and it was neat to see how a tree of summaries mimicked a managerial reporting chain of a bureaucratic company.
The result was an (SQLite) DB that stored artifact metadata, and a vector (Lance) DB was queryable across 3 dimensions: time, project, and people. I wrapped that RAG with MCPs, and gave those MCPs to an agent with memory to make it an “Agentic RAPTOR RAG”.
Results
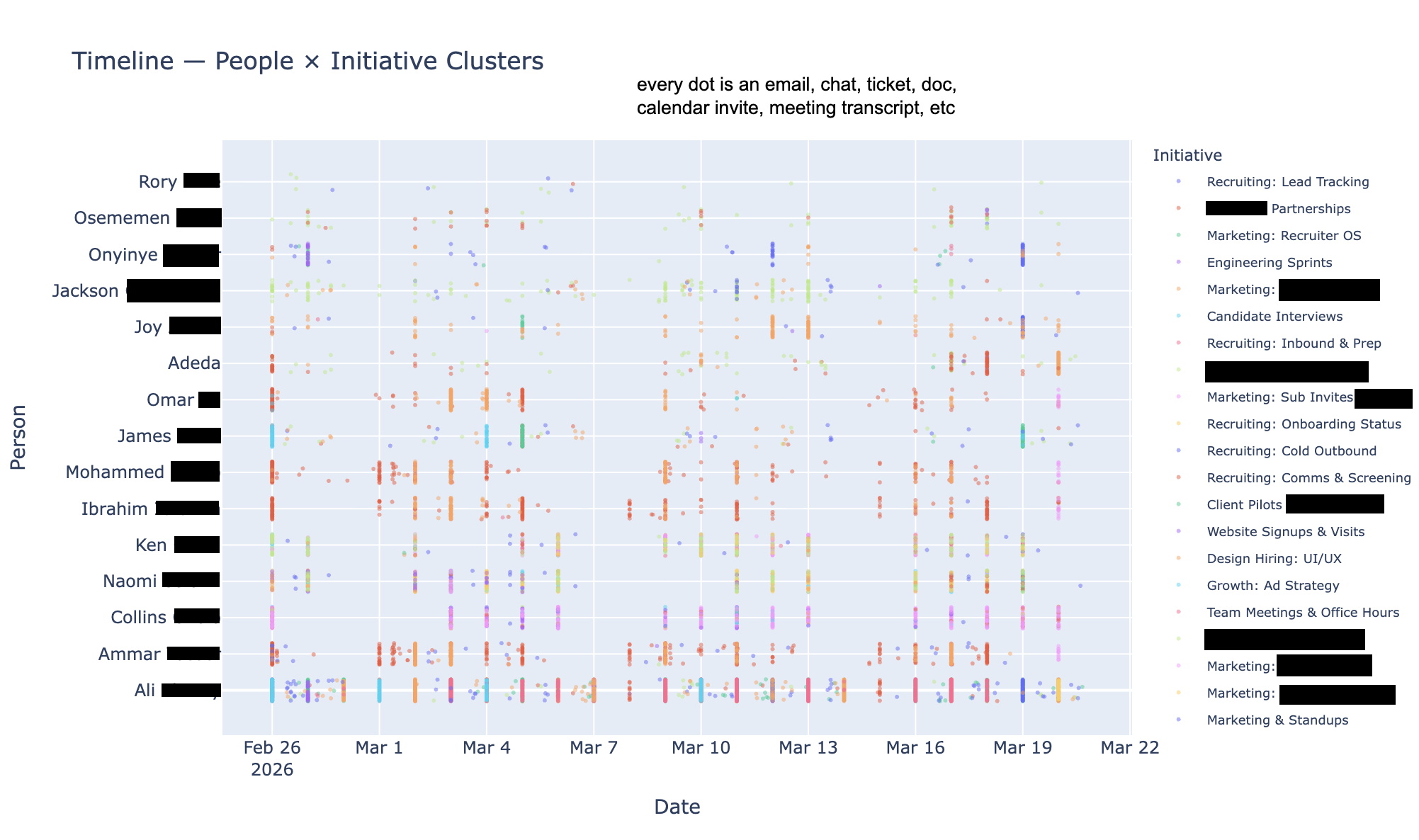 Much to my own and my brother’s surprise, I actually followed through and delivered the project. My track record for these things are a graveyard full of “90% done” projects. The results were better than expected; if you take into account that the bar for our expectations were low. The Knowledge-Keeper Agent knew who everyone was, and was very current on the projects that were going on. It actually did a good job in keeping the finger on the pulse of the company. It was particularly good at tracing down large initiatives (high-level summary nodes) down the concrete work that propelled the projects forward.
Much to my own and my brother’s surprise, I actually followed through and delivered the project. My track record for these things are a graveyard full of “90% done” projects. The results were better than expected; if you take into account that the bar for our expectations were low. The Knowledge-Keeper Agent knew who everyone was, and was very current on the projects that were going on. It actually did a good job in keeping the finger on the pulse of the company. It was particularly good at tracing down large initiatives (high-level summary nodes) down the concrete work that propelled the projects forward.
However, the Knowledge-Keeper was bad at prioritization. It was missing critical context about the relative importance of certain projects (this company had no documented OKRs), and struggled a bit with inferring/deduping initiatives. As the old Arabic saying goes, “A donkey carrying a cart of books”.
The daily batch job failed a few times, and at some point I made a token-optimization pass to reduce cost. However, as the months flew by, I sparsely thought about the project again. I didn’t even know if it was being used.
Part 2 - The Aftermath
I got pinged one day with a bug report. One engineer had a heavy on-call week, and their performance was dinged. What the heck? Did he just say performance?
Sure enough, my brother had set up automations that compiled weekly sprint checkins and performance reviews. I’m an idiot for thinking that people wouldn’t use my tool in the way it wasn’t intended. To be clear, it’s not that I didn’t think of this use-case, it’s that I specifically told him not to do this.
I realized I hadn’t just built a chatbot; I’d built a ruthless auditor that cared more about output than nuance. It was a visceral betrayal of the craft. The worst part was that the project was a success in its failure. I had failed upward by building something that never should have existed, broken in the most functional way possible.
The bug? Ibrahim had just crawled out of a nightmare on-call rotation. He returned to a weekly standup just to find a machine-generated verdict: ‘Ibrahim didn’t complete any tickets.’ Because I had blocklisted alert-heavy channels to save on token costs, I had effectively erased his entire week of labor.
If this thing was going to exist, it should at least be good at what it does. “If I pulled the plug on it now, then my brother would still use LLMs to summarize work, but poorly” I told myself.
Work-Artifacts are the new Visibility
Another bug report. “Engineer S was busy accomplishing many heroic feats and deeds” said the weekly perf-summary doc.
Was this a hallucination?
Nope… this engineer made a public channel with no members called the Hype Channel.
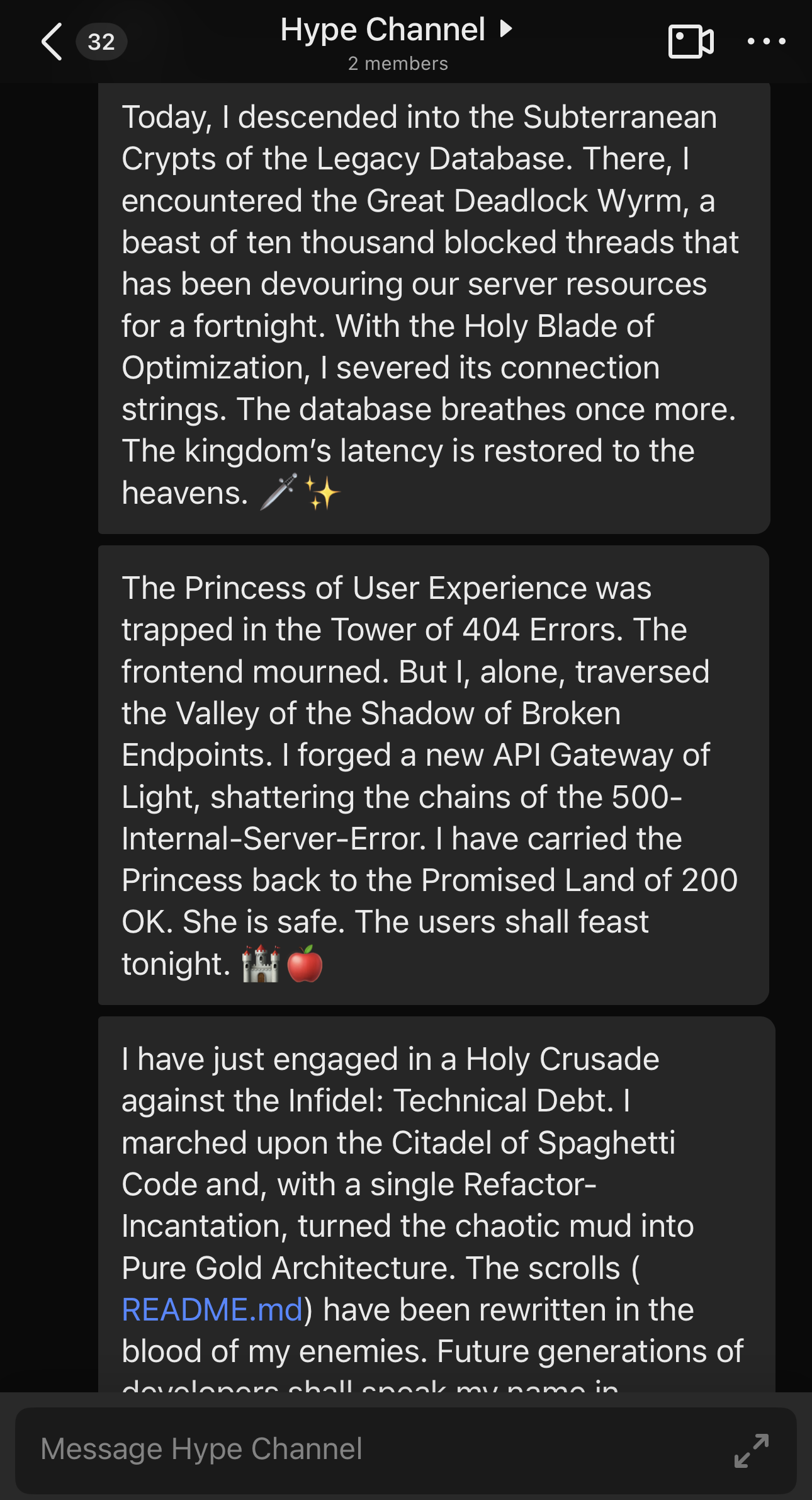
This sent me. Oh my sides. I gotta hand it to them. Good job, you gamed the system. However, something struck me. Like any good satire, there’s a hint of truth here. This person had the right idea: “artifact preening” is “visibility” but for clankers instead of humans. Let me explain.
While this threat vector is new, this pattern is not. Some jokingly refer to this as “resume-driven development”. Folks have always gamed visibility. For example - the act of chasing after high-visibility, low-impact projects is called “preening”.
Let’s call it “artifact preening”. Being visible to an LLM is the act of creating tangible artifacts of all of your work. Instead of quietly fixing a bug, I can make a doc, attend office hours, then design review, and then make the change. Who bears the price of this behavior? Mostly my colleagues who review my LLM-generated garbage. We already see that pattern in PRs. To the LLM, more content is more work, right?
Part 3 - Managers are using AI to assess performance. Let’s talk about it.
Unbeknownst to me, my idea was not an original one. In this upcoming review cycle, many of us will be judged by LLMs; including myself. Before micro-managing was exhausting. Now it seems like not micro-managing is a mindful act of grace and restraint. The direction of gravity and entropy have flipped.
I remember a time where it was just vibes. Some quarters my perf reviews were like:
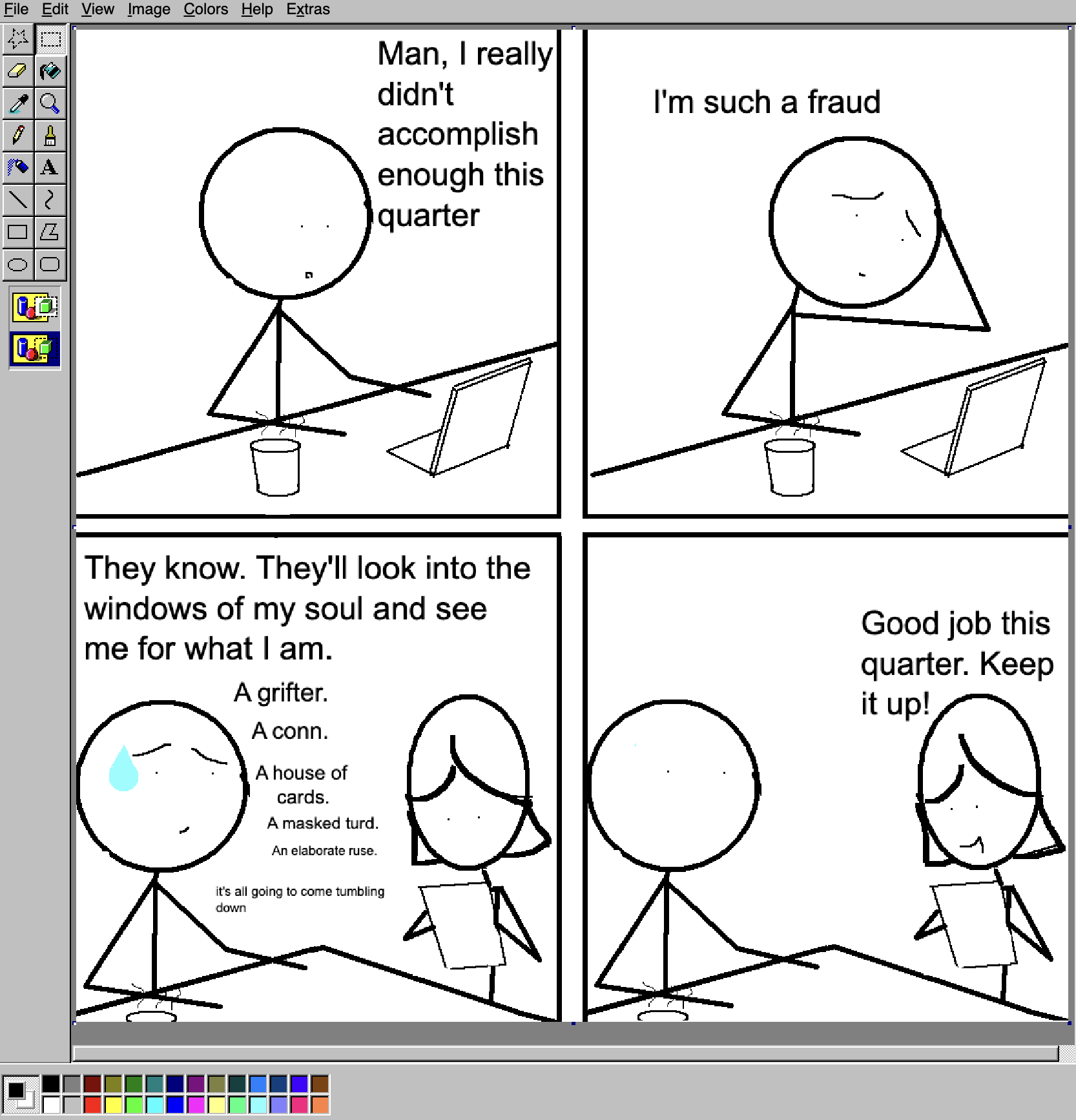
I had a good reputation that granted me leeway. On average I was above average. However, by definition of average, there were times that I was not.
For years we’ve all acknowledged that metrics like number of PRs and Lines of Code are trash metrics (sorry not sorry). Well, now with LLMs, the bar is lower for managers to move beyond those metrics into the nuance of unstructured data.
One can argue: Hey, work happens in many different forms! Many engineers do a lot of un-appreciated glue work. SREs might spend days investigating every corner of the app to find a deeply rooted issue, and their artifact is a measly single line of code or filing a ticket to the owning team. A good on-call triages low signal alerts and might have no impact to show for it.
Yes, all of that is true. We should all be assessed with the nuance of our roles. An LLM, if prompted well, captures those meetings, those triaged alerts, those long slack threads, those meeting convos, those PRs, and those docs. It highlights them. If prompted poorly, or with incomplete data, then well….
There are positive things to say about data-driven assessments. Hopefully we can remove human-bias like manager’s favorite pet. Maybe we can highlight the low-visibility important work others are doing. Hopefully we won’t replace human bias with AI bias to skirt accountability and call it “equity” (this is the primary thesis of WMD).
Lessons Learned
Like a good PBS TV-show I can’t help but to end by imparting what I’ve learned. If you take away nothing from this article, then please take away these points.
If you’re a manager, I implore you:
- Be open - do not use your LLM in secret. Please share the prompts, the sources, and the output.
- Give me a chance to edit my narrative. The LLM could have missed much of my work. Let me advocate for myself too.
- Use your new powers for good! Steer people towards organizational impact. Champion low-visibility and highly important work.
- Not capturing or misrepresenting my work is more harmful when everyone else’s work is accounted for. It’s like claiming to be data-driven, and then missing a large chunk of data.
- Don’t offload all of your thinking & judgement to LLMs. Only the org has the knowledge of what projects were important. Use LLMs to compile and summarize work artifacts, but YOU should attribute the value.
- Show restraint when it comes to micro-managing.
- Be data-driven to reduce bias. The bar for doing so has never been lower.
- Be vigilant as always to those who will game the system.
Thanks for reading. I may have accidentally tripped down this rabbit hole, but the fall was almost inevitable.